
In this area, significant progress has been achieved, but the
main problem of modern speech recognition is to achieve the
robustness of the process.In this method there are various advantages
such as good account of temporal structure of speech
signal (shear strength), resistance to the variance signal resistance
to noise, low resource consumption, size of the
dictionary. but the problem is that for high-quality speech
recognition to match these benefits in the same
method of recognition
In speech recognition takes into
account the following :
Speech Variation due to:
local distortion of scale,
interaction (spirit) sounds intonation,the human condition.
· Speech
signal Variability due to: conditions
of entry (distance from the recording device, its
features, etc.), score of ambient sound (noise).
Speech Technology
Speech recognition is the process of
extracting text transcriptions or some form
of meaning from speech input.Speech analytics can be
considered as the part of the voice processing, which
converts human speech into digital forms
suitable for storage or transmission computers.
Speech
synthesis function is essentially reverse speech
analysis-they convert speech data from digital form to
one that is similar to the original entry and is
suitable for playback.Speech analysis processes can also be
called digital speech coding (or encoding) and
The problem of temporary distortions was
that speech comparison samples of the same class can be
used only if the timescale conversions of one of them. In
other words, say the same sound with different
durations, and Moreover, the various parts
of the sounds may have different duration as part of a
class. This effect allows you to talk about
“local distortions of scale along the time axis.
Reduce the Value of Artificial Neural Networks
Neural network speech recognition scheme implies
a number equal to the number of classes of
recognition. Each entry gives a value to
indicate the probability of belonging to a given class, or
a measure of closeness of this fragment to
this speech resolves to sound. For simplicity we confine
ourselves to describing a class of pattern recognition.
Our reasoning without losses can be transferred to a
more general case.
Usually the voice signal is broken into
small pieces-frames (segments), each frame is subjected
to pre-treatment, for example, by using
the window Fourier transform. This is done to
reduce space and increase of
attributive stripped classes .
As a result, each frame is characterized by the set
of coefficients, called acoustic characteristic vector.
Methods
For the application of the
method of reducing the value of artificial neural
network for recognition of phonemic tasks we need
to choose a target function and analyze its properties.
One of the problems with speech recognition is that you
cannot select a stand-alone speech sound. The form of
sound is very dependent on the sound environment of a
Signal that goes after him, and the sound
that goes before him.It is known that waveform is
a smooth transition from one sound to another.
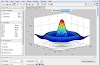
Properties of functions P(t,Ω):
P(t,Ω)=0 and P(t,Ω)<ε0 If the beep sound is not Ω, or
is not a speech anyway, where ε on 0 threshold
is close to zero;
P
(t, Ω) = 1 if the beep is sound;
P (t, Ω) ∈ (0.1) in the
zone of phonemic interface, and P is the phonemic seamlessly
interface to sound and gradually decreases in the phonemic joint after.
Conclusion
Use model of speech recognition based on artificial
neural networks. Training the neural network approach is being
developed using genetic algorithm. This approach will
be implemented in the system identification numbers. Coming
to the realization of the system of recognition of voice
commands It is also planned to develop system of automatic
recognition of speech keywords that are
associated with the processing of telephone calls
or area security.



















{kind=link}
0 Comments